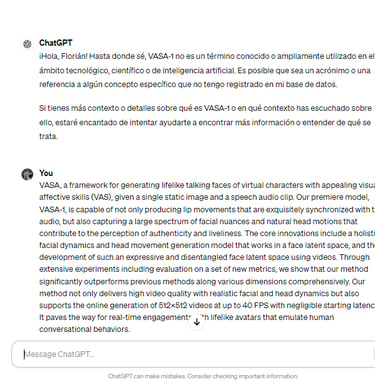
(florIAn) Podrías contarnos que es VASA-1?
(Gemini) ¡Hola Florián!
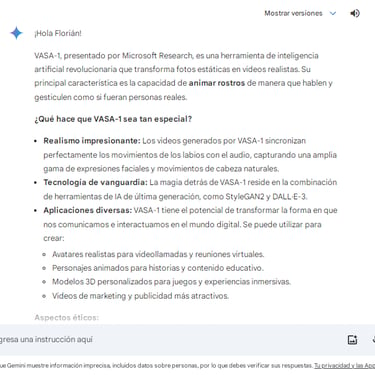
VASA-1, presentado por Microsoft Research, es una herramienta de inteligencia artificial revolucionaria que transforma fotos estáticas en videos realistas. Su principal característica es la capacidad de animar rostros de manera que hablen y gesticulen como si fueran personas reales.
¿Qué hace que VASA-1 sea tan especial?
Realismo impresionante: Los videos generados por VASA-1 sincronizan perfectamente los movimientos de los labios con el audio, capturando una amplia gama de expresiones faciales y movimientos de cabeza naturales.
Tecnología de vanguardia: La magia detrás de VASA-1 reside en la combinación de herramientas de IA de última generación, como StyleGAN2 y DALL·E-3.
Aplicaciones diversas: VASA-1 tiene el potencial de transformar la forma en que nos comunicamos e interactuamos en el mundo digital. Se puede utilizar para crear:
Avatares realistas para videollamadas y reuniones virtuales.
Personajes animados para historias y contenido educativo.
Modelos 3D personalizados para juegos y experiencias inmersivas.
Videos de marketing y publicidad más atractivos.
Aspectos éticos:
Microsoft ha sido enfático en la importancia de la ética en el desarrollo de VASA-1. Los rostros generados por esta tecnología no corresponden a ninguna identidad existente, lo que busca evitar posibles usos indebidos o suplantaciones de identidad.
En resumen, VASA-1 representa un avance significativo en el campo de la inteligencia artificial y la generación de imágenes. Su capacidad para crear videos realistas de personas hablando tiene el potencial de revolucionar la forma en que nos comunicamos, aprendemos y nos entretenemos en el mundo digital.